📆 ThursdAI - Aug 14 - A week with GPT5, OSS world models, VLMs in OSS, Tiny Gemma & more AI news
Episode Description
Hey everyone, Alex here 👋
Last week, I tried to test GPT-5 and got really surprisingly bad results, but it turns out, as you'll see below, it's partly because they had a bug in the router, and partly because ... well, the router itself! See below for an introduction, written by GPT-5, it's actually not bad?
Last week was a whirlwind. We live‑streamed GPT‑5’s “birthday,” ran long, and then promptly spent the next seven days poking every corner of the new router‑driven universe.
This week looked quieter on the surface, but it actually delivered a ton: two open‑source world models you can drive in real time, a lean vision‑language model built for edge devices, a 4B local search assistant that tops Perplexity Pro on SimpleQA, a base model “extraction” from GPT‑OSS that reverses alignment, fresh memory features landing across the big labs, and a practical prompting guide to unlock GPT‑5’s reasoning reliably.
We also had Alan Dao join to talk about Jan‑v1 and what it takes to train a small model that consistently finds the right answers on the open web—locally.
Not bad eh? Much better than last time 👏 Ok let's dive in, a lot to talk about in this "chill" AI week (show notes at the end as always) first open source, and then GPT-5 reactions and then... world models!
00:00 Introduction and Welcome
00:33 Host Introductions and Health Updates
01:26 Recap of Last Week's AI News
01:46 Discussion on GPT-5 and Prompt Techniques
03:03 World Models and Genie 3
03:28 Interview with Alan Dow from Jan
04:59 Open Source AI Releases
06:55 Big Companies and APIs
10:14 New Features and Tools
14:09 Liquid Vision Language Model
26:18 Focusing on the Task at Hand
26:18 Reinforcement Learning and Reward Functions
26:35 Offline AI and Privacy
27:13 Web Retrieval and API Integration
30:34 Breaking News: New AI Models
30:41 Google's New Model: Gemma 3
33:53 Meta's Dino E3: Advancements in Computer Vision
38:50 Open Source Model Updates
45:56 Weights & Biases: New Features and Updates
51:32 GPT-5: A Week in Review
55:12 Community Outcry Over AI Model Changes
56:06 OpenAI's Response to User Feedback
56:38 Emotional Attachment to AI Models
57:52 GPT-5's Performance in Coding and Writing
59:55 Challenges with GPT-5's Custom Instructions
01:01:45 New Prompting Techniques for GPT-5
01:04:10 Evaluating GPT-5's Reasoning Capabilities
01:20:01 Open Source World Models and Video Generation
01:27:54 Conclusion and Future Expectations
Open Source AI
We've had quite a lot of Open Source this week on the show, including a breaking news from the Gemma team!
Liquid AI's drops LFM2-VL (X, blog, HF)
Let's kick things off with our friends at Liquid AI who released LFM2-VL - their new vision-language models coming in at a tiny 440M and 1.6B parameters.
Liquid folks continue to surprise with speedy, mobile device ready models, that run 2X faster vs top VLM peers. With a native 512x512 resolution (which breaks any image size into 512 smart tiles) and an OCRBench of 74, this tiny model beats SmolVLM2 while being half the size. We've chatted with Maxime from liquid about LFM2 back in july, and it's great to see they are making them multimodal as well with the same efficiency gains!
Zhipu (z.ai) unleashes GLM-4.5V - 106B VLM (X, Hugging Face)
In another "previous good model that now has eyes" release, the fine folks from Zhipu continued training thier recently released (and excelled) GLM 4.5-air with a vision encoder, resulting in probably one of the top vision models in the open source!
It's an MoE with only 12B active parameters (106B total) and gets SOTA across 42 public vision-language benches + has a "thinking mode" that reasons about what it sees.
Given that GLM-4.5Air is really a strong model, this is de fact the best visual intelligence in the open source, able to rebuild websites from a picture for example and identify statues and locations!
Jan V1 - a tiny (4B) local search assistant QwenFinetune (X, Hugging Face)
This one release got a lot of attention, as the folks at Menlo Research (Alan Dao who came to chat with us about Jan on the pod today) released an Apache 2 finetune of Qwen3-4B-thinking, that's focused on SimpleQA.
They showed that their tiny model is beating Perplexity Pro on SimpleQA.
Alan told us on the pod that Jan (the open source Jan app) is born to be an open source alternative to searching with local models!
The trick is, you have to enable some source of search data (Exa, Serper, Tavily) via MCP and then enable tools in Jan, and then.. you have a tiny, completely local perplexity clone with a 4B model!
Google drops Gemma 3 270M (blog)
In some #breakingNews, Google open sourced a tiny (270M) parameters, "good at instruction following" Gemma variant. This joins models like SmolLM and LFM2 in the "smol models" arena, being only 300MB, you can run this.. on a toaster. This one apparently also fine-tunes very well while being very energy efficient!
Big Companies (AKA OpenAI corner this past 2 weeks)
Ok ok, we're finally here, a week with GPT-5! After watching the live stream and getting access to GPT-5, my first reactions were not great. Apparently, so have other peoples, and many folks outcried and complained about the model, some even yelling "AGI is cancelled".
What apparently happened is (and since, been fixed by OpenAI) is that GPT-5 wasn't just a model that launched, it was a "smart" router between a few models, and not only did they have a routing bug, the basic GPT-5 model, the one without thinking, is... not great.
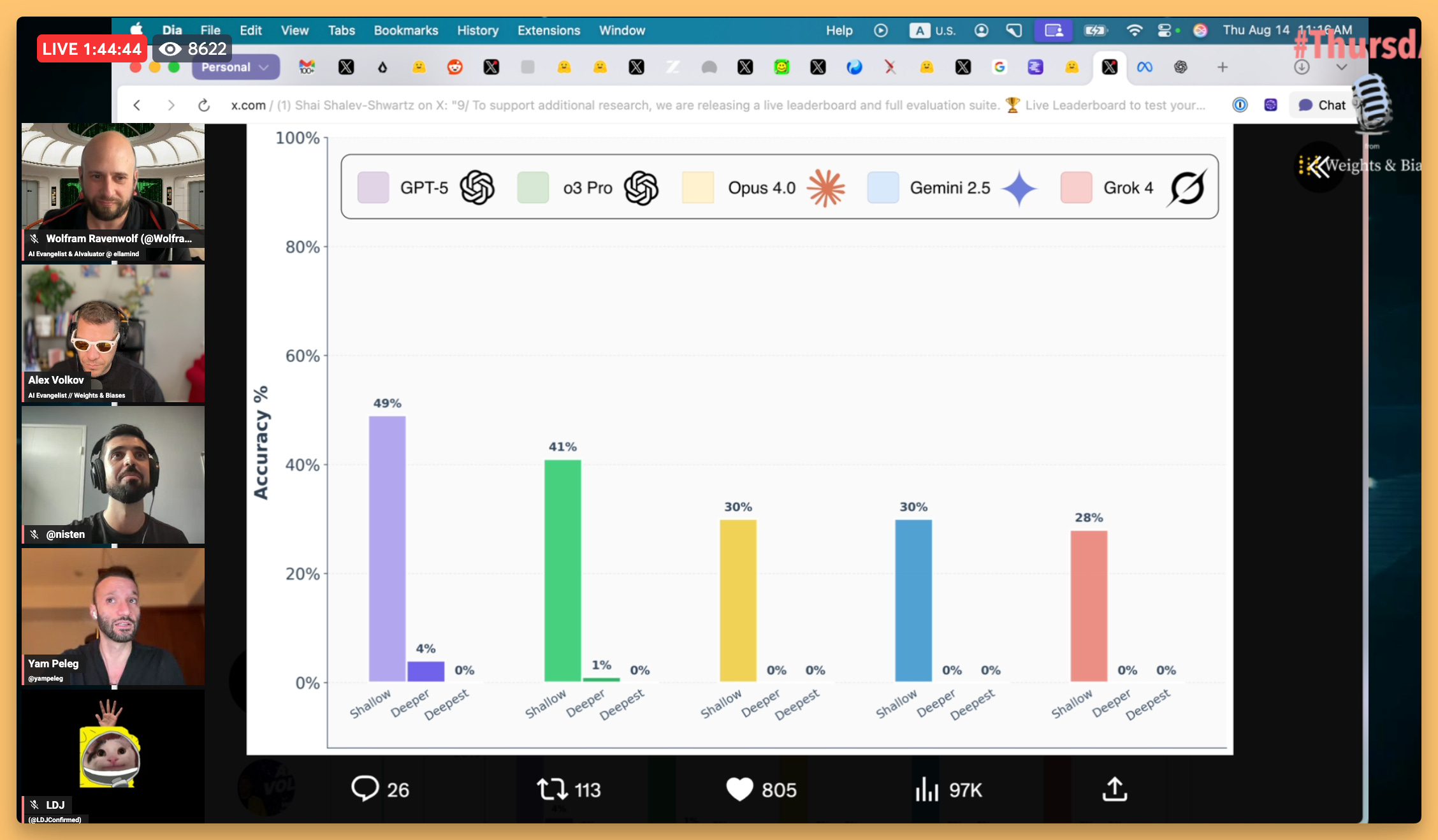
But the thinking GPT-5, the one that the router refused to send me to, is really good (as confirmed independently by multiple evals at this point)
For one, it's the most accurate function calling model on OpenRouter
It's also one of the best on this new FormulaOne benchmark that was just launched
You're prompting it wrong!
Apparently, not only is GPT-5 more intelligent, it's also significantly "surgical" in instruction following, and so, for many folks, just replacing GPT-5 into their tools or prompts didn't just "work", as this model, more than before, is sensitive to conflicting things in the prompt.
OpenAI has released a guide for prompting the model, mostly aimed at developers (as users shouldn't be learning to prompt as models get more intelligent) + they also released a prompt optimizer! Just dump your long and complex prompts in there, and you'll get an updated prompt with explanations of why they changed what they changed!
Model Picker (and legacy models) are back!
So, OpenAI tried and super quickly reversed course on removing the "model picker". At first, it was only GPT-5 there, but many people complained about the abrupt removal of 4o, their .. favorite models. At first, OpenAI added back the models via a hidden setting, and later, they have added 4o back to everyone by default, while increasing the reasoning quota to 3000 messages per week!
Generally, my thoughts are, if you've tried GPT-5 and weren't impressed, give it another go! (especially now that it's connected to Gmail in chats!)
Other notable Big Company updates
In other news, Claude has extended the context window of Sonnet to 1M in the API, and apparently both Claude and Gemini have been adding memory features!
Grok video has been catching up and is now free for a while to all users
This Week's Buzz: Weave DX improvements
Quick update from my day job at Weights & Biases - we've rolled out some quality-of-life improvements to Weave, our LLM observability platform. We now have a unified assets tab where you can manage all your prompts, models, and datasets with full versioning support.
Prompts are being version tracked, so if you use that GPT-5 prompt optimizer, we'll store all the previous revisions for ya!
The coolest addition? Threads! Perfect for tracking agent executions or grouping related API calls. You just add a thread_id to your traces and Weave handles the rest. If you're building AI applications and not tracking everything, you're flying blind - give Weave a try at wandb.me/weave!
World models are getting... open sourced!
I still think that Google's Genie-3 release from last week was maybe the more important one, though we didn't really get to play with it yet!
And while getting excited by world models, I was thinking that it's goig to take a while for Open Source to catch up. But this week, not 1, but two world models were open sourced, making me think that we'll get to generated worlds quicker than I expected and the race has begun!
Skywork's Matrix-Game 2.0 (project, HF)
Matrix-game 2 is a auto-regressive diffusion model, that was trained on 1200 hours of Unreal Engine and GTA-5 environments that runs at 25 frames per second!
It works by creating an "action injection module" that embeds the mouse/keyboard inputs into the generation, enabling frame-level controls.
Hunyuan open-sources GameCraft for real-time, high-dynamic game video generation (X, Hugging Face)
Two world-models (well, game models) in the same week? Tencent (who had Hunyuan video before) have trained a game engine on top of their excellent HY-video and have shown the same examples, of building a full world based on a few images.
Their pipeline trained on 1M game play clips from AAA titles, and they also map W/A/S/D and mouse signals into continuous camera/action embeddings, allowing for control and angle creation.
The cool thing? A quantized 13B version supposedly can run on a RTX 4090!
Funnily, they already had Matrix-Game (the one that came out a few days before) benchmarked and beat on the release today!
Genie 3 is not messing around
While all the open source is impressive, I was… absolutely blown away by this video from an artist who got the Genie3 team to extend a video of his. Just look at the collision of the plane with the sphere, out of nowhere, Genie3 adds a shadow, and then collision mechanics, the plane bouncing off, and even the jet trails subside and then resume! It really really is crazy to imagine that no prompting was given and the model just.. knew how to do this!
Phew, that was a lot! Much more as always on the actual show, despite it being a "quiet" week by summer of 2025 standards, there was a LOT of open source releases and GPT-5 situation shows that even OpenAI can stumble on new tech releases!
Keep the feedback coming - find me on Twitter/X at @altryne or email the show. And remember, if you want to catch all the technical details and demos, the video version on YouTube has everything the podcast can't show.
Until next week, keep tinkering, keep questioning, and keep pushing the boundaries of what's possible with AI!
See you next ThursdAI 🚀
TL;DR - All Topics Covered
Hosts and Guests
* Alex Volkov - AI Evangelist @ Weights & Biases (@altryne)
* Co-hosts: @WolframRvnwlf, @yampeleg, @nisten, @ldjconfirmed
* Guest: Alan Dao from Jan (@jandotai)
Open Source LLMs
* Liquid AI LFM2-VL: 440M & 1.6B vision-language models with 2x GPU speedup (Blog, HF)
* Jan V1: 4B parameter search assistant beating Perplexity Pro on SimpleQA (X, HF)
* GPT-OSS Base: Reverse-engineered base model from Jack Morris (X Thread)
* Gemma 3: Google's 270M parameter model with strong instruction following (HF)
* Meta Dino v3: Self-supervised vision model for segmentation (Blog)
Big Companies & APIs
* Mistral Medium 3.1: New model on Mistral platform
* Gemini & Claude: Added memory/personalization features
* GPT-5 Updates: Router fixes, model selector returned, prompting guide released (Guide, Optimizer)
* Claude Sonnet 4: 1M token context window (Announcement)
This Week's Buzz
* Weave updates: Unified assets tab and threads for agent tracking
* New features for LLM observability and evaluation
Vision & Video
* Hunyuan Large Vision: 1B vision encoder + 389B MoE language model (Project)
* GLM-4.5V: 106B open source VLM from Zhipu AI (X, HF)
World Models
* Matrix Game 2.0: Real-time interactive world model, 25fps generation (Project, HF)
* Hunyuan GameCraft: Game video generation with physics understanding (X, HF)
Tools
* Grok: Now includes video generation for all users
* Jan Desktop App: Local AI with MCP support and search capabilities
This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit sub.thursdai.news/subscribe